






基因是一段携带有遗传信息的DNA序列,通过转录和翻译,指导蛋白质的合成来表达个体所携带的遗传信息从而控制生物的性状表达。
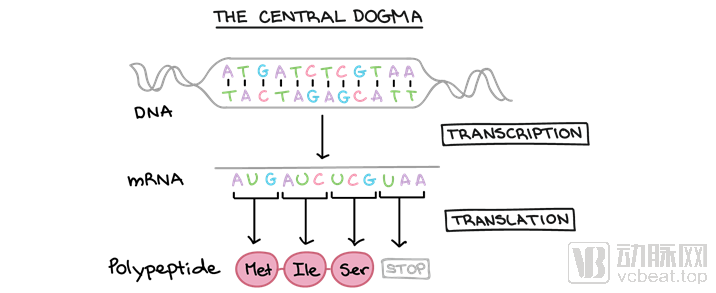
中心法则(The central dogma):是指遗传信息从DNA转录(Transcription)成RNA,再从RNA翻译(Translation)成蛋白质,即完成遗传信息的转录和翻译的过程。(图片引用自Khan Academy)
基因检测则是通过血液、体液或细胞对DNA进行检测的技术,通过特定设备对被检测者细胞中的DNA分子信息作检测,分析它所含有的基因类型和基因缺陷及其表达功能是否正常的一种方法。基因检测是融合了分子生物学、检验医学和生物信息学多个学科的一种专业的检测。
如何证明基因检测的准确性,业界似乎没有找到相应的简单易懂的说明。在此结合笔者的临床实践,试着与大家分享一下,读者可能是对基因检测比较关心的一般用户或者专业人士,我们期待同行读后的进一步探讨交流,以期共同推动基因检测行业的发展。
1所谓“检测的准确性”
当提出“检验结果准吗?”这样的问题时,普遍都关心两个方面:第一方面是检测结果数据的准确性;第二方面是依据检测结果对人体健康状况(如是否患病)进行判定的准确性。前者是计量学关心的问题,后者是临床应用问题,临床实验室结果的临床应用是最终目的。
一般来说,大众理解的“检测的准确性”是指当我们拿到一份检验报告单时,特别是检验结果出现异常时,首先考虑的检验结果是否准确。在临床实践中,多为检测指标是否在正常范围内(如红细胞数量),或检测指标的阴阳性(如乙型肝炎病毒的抗原抗体检测)。这样的结果是直接可读,并在大量的既往工作中取得了临床验证的指征。因此,这样的结论可以说,绝大多数情况下符合临床表现。
但这样的评价标准无法沿用至基因组变异与疾病相关领域,这是一个新兴的领域,是人类对未知事物探索迈出的第一步,是在黑暗中摸索石头,并踩着过河的一个漫长过程。在这个过河的过程中,我们有已经摸得很清楚的石头,也有摸得不那么清楚的石头,还有摸错了的石头,甚至有些地方还不知道有没有石头。所以要定义我们基于二代测序的罕见遗传病分析是否“检测准确”,就不能一概而论,而需要一些详细的梳理。
那就必须从测序原理、疾病数据库和生物信息分析发展与技术进步几个方向进行阐述。
2测序原理及测序的准确性
DNA测序技术,即测定DNA碱基排列顺序的技术。人类基因组由腺嘌呤(A)、鸟嘌呤(G)、胸腺嘧啶(T)和胞嘧啶(C)四种脱氧核糖核酸以不同排列组成。测定其排列顺序,即可进一步研究或改造目的片段。根据出现时间的先后顺序,以及测序方案的不同,目前测序技术大致可分为一代测序(Sanger测序),二代测序(Illumina、Thermofisher、华大基因等)和三代测序(Oxford Nanopore Technology、PacBio等)。

历代测序仪发展,一代测序仪明确是ABI(现Thermo Fisher)的Sanger测序;二代测序仪起源于Roche 454,现包括illumina、Thermo Fisher(Ion Torrent)、华大基因等品牌;三代测序目前主要是PacBio和ONT。但国内最近已有2家测序公司(齐碳科技、今是科技)研发出了三代纳米孔测序仪。
尽管我们用一代、二代、三代来比较容易的区分这些测序技术,但是总的来说,这些测序技术在业内都可以细分,比如Illumina的我们称为基于簇生成原理的高通量测序,而ONT的我们则称为纳米孔测序技术。其实,这三代技术没有哪一种技术要优于其他,也没有哪一种技术在目前能将其他技术取代,而是根据具体的检测需要在最佳的应用场景得到使用,这就是目前测序领域的现状。下面简单介绍一下几个类型的测序技术及优劣势。
一代测序:Sanger法测序的原理就是利用一种DNA聚合酶来延伸结合在待定序列模板上的引物,直到掺入一种链终止核苷酸为止。每一次序列测定由一套四个单独的反应构成,每个反应含有所有四种脱氧核苷酸三磷酸(dNTP),并混入限量的一种不同的双脱氧核苷三磷酸(ddNTP)。由于ddNTP缺乏延伸所需要的3-OH基团,使延长的寡聚核苷酸选择性地在G、A、T或C处终止,终止点由反应中相应的双脱氧而定,可通过高分辨率变性凝胶电泳分离大小不同的片段从而了解到DNA的排列顺序。经多年发展,一代测序已相当完善,是目前所有基因检测的国际金标准。在临床上,所有的DNA多态性验证几乎都是用一代测序完成。二代测序与三代测序也多是用一代测序来进行验证。2010年以来,虽然出现了很多新一代测序仪产品,但仍由一代测序发挥其精准优势用于临床检测和验证。
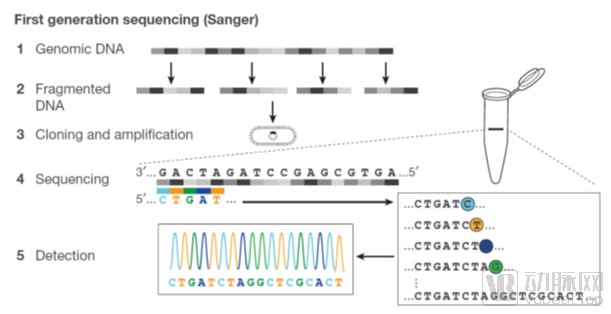
Sanger双脱氧链终止法是根据核苷酸在某一固定的点开始,随机在某一个特定的碱基处终止,并且在每个碱基后面进行荧光标记,产生以A、T、C、G结束的四组不同长度的一系列核苷酸,然后在尿素变性的PAGE胶上电泳进行检测,从而获得可见DNA碱基序列的一种方法。
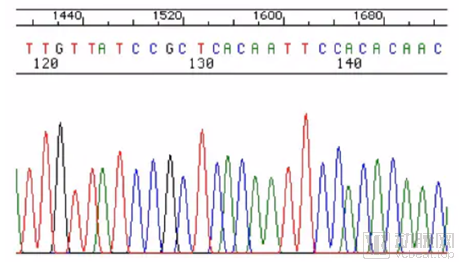
一代测序结果图,横轴是电泳时间,纵轴是荧光强度,横轴也是碱基的先后次序。峰越高、越尖,与别的峰交错越少,则这个碱基判读准确性越好。结果肉眼可见,直观而准确。
二代测序:第二代DNA测序技术又称高通量测序技术(High-throughput sequencing, HTS),以低成本、较高的准确度,一次可对几百、几千个样本的几十万至几百万条DNA分子同时进行快速测序分析。这一时期的代表技术有 Roche公司的454(已退市)、Illumina公司的Solexa(已升级到Novaseq,市场份额第一)和ABI公司的SOLID(由ThermoFisher公司收购,已升级到Ion Torrent S5),由于该时期的测序技术十分前沿,因而市场主要被这三家公司所垄断。其测序技术复杂,生成测序文件数据量巨大,后续生物信息处理难度高,因此近5年才逐步进入临床,且多用于肿瘤精准用药的部分。
以illumina为例,我们简单介绍一下其测序流程。
①将目的DNA分子打断成100-200 bp的片段,随机连接到固相基质上,经过Bst聚合酶延伸和甲酸胺变性的桥PCR循环,生成大量的DNA簇(DNA cluster),每个DNA 簇中约有超过1000个相同序列的DNA片段。
②之后的反应与Sanger法类似,加入用4种不同荧光标记并结合了可逆终止剂的dNTP。固相基质上每个孔有八道独立检测的位点,所以一次可以并行八个独立文库,可容纳数百万的模版克隆,可把多个样品混合在一起检测,每个固相基质上一次可读取10亿个碱基。
③DNA簇与单链扩增产物的通用序列杂交,由于终止剂的作用,DNA聚合酶每次循环只延伸一个dNTP。每次延伸所产生的光信号被标准的微阵列光学检测系统分析测序,下一次循环中把终止剂和荧光标记基团裂解掉,然后继续延伸dNTP,实现了边合成边测序技术。
④其主要的缺点是由于光信号衰减和移相的原因使得序列读长较短,可以进行每个DNA测序片段的阅读长度较短,目前主流且成本最低的就是做双端测序150bp(PE150)。我们测全外显子组的策略也是PE150。
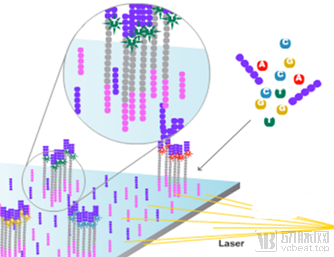
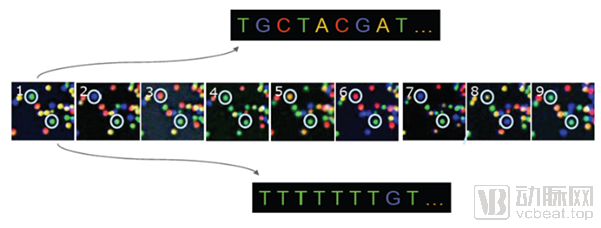
二代测序原理,通过簇生成,CCD捕获结合到模板的dNTP发的荧光,确定其DNA序列。
二代测序完成后,由于数据量巨大,复杂和多样,因此,结果是肉眼不可见的,需要专业的算法、流程将原始数据处理为可用的数据。可比喻为,测序只是去菜场买菜,算法则是把菜做成大餐的过程。这个过程需要超级计算机,建立好的优秀算法以及精通生物信息学分析的人员。
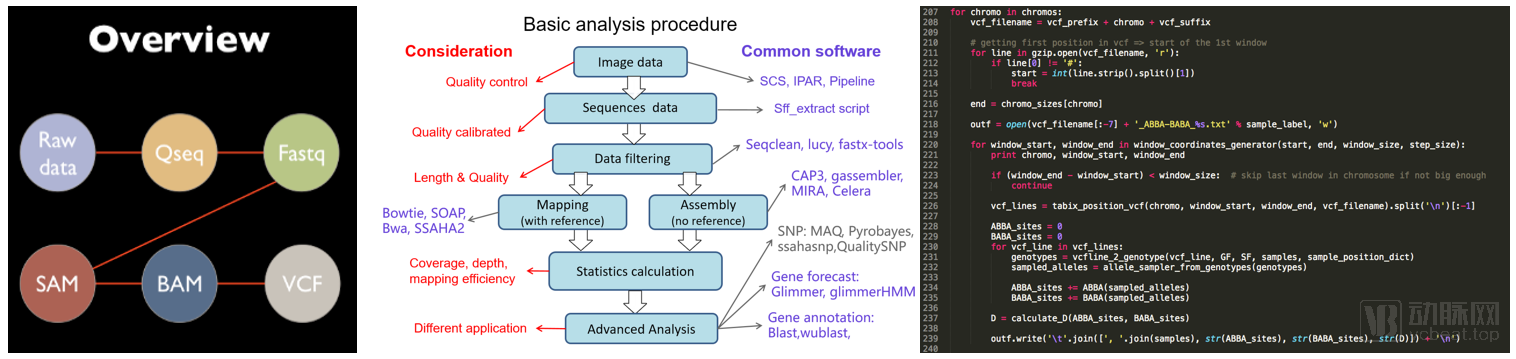 二代测序分析流程中,需要将原始测序数据进行质控后生成一系列的中间文件(左图),通过繁琐的生物信息学流程(中图),最后拼接成我们想要的基因。目前全流程多用Python和Perl语言在服务器上实现(右图)。
二代测序分析流程中,需要将原始测序数据进行质控后生成一系列的中间文件(左图),通过繁琐的生物信息学流程(中图),最后拼接成我们想要的基因。目前全流程多用Python和Perl语言在服务器上实现(右图)。
二代测序由于其原理的一些问题,导致必须同一个位点测多次,才能保证数据的可靠性。一般用于临床的数据,需要同一位点测序后出现200次以上。我们将这样的方案叫做测序深度(>200 X)。二代测序的优势是巨大的,其数据量巨大,可短时间高效率对人类基因组测序,并发现大量未知位点。单个位点成本降低,是个性化医疗和精准用药的基础。
最后,还有一种类似测序的工具,叫做基因芯片。基因芯片的原型是80年代中期提出的。基因芯片的测序原理是杂交测序方法。目前由国内外几家大厂家所垄断。其优点是信息量较大,比一代测序的识别位点极大提升,可批量化生产并有完全标准流水线工作。但其缺点也很明显,成本仍较高,无技术门槛,只检测已选择好的位点,更新位点的时间和经费成本较高。比如illunima公司的ASA芯片,就是在一块芯片上集成了66万个人类基因组位点,检测信息量大约30m左右。
2001年,通过一代测序,耗资37亿美元,耗时13年,获得了人类基因组草图。到了2007年,用二代测序完成第一个完整的人类基因组序列图谱只花费了150万美元,耗时3个月。到了2020年,人类基因组测序只需要不到1万元人民币即可完成测序工作,时间只需要3天。近年来,测序技术突飞猛进,随着测序单价的不断降低,我们必将见证人人都有“基因身份证”的那一天。
3基因突变与疾病的关系
中国民间流传千百年的俗语非常生动形象地描述了基因的主要特征——遗传和变异。
“龙生龙,凤生凤”是遗传;“龙生九子,各有不同”是因为基因的变异。遗传与变异,是生物界不断地普遍发生的现象,也是物种形成和生物进化的基础。人类基因的遗传与变异,与环境共同作用,决定了人的生、长、老、病、死。现代医学研究证明,所有的疾病,除了外伤、中毒或营养不良以外,几乎都跟基因有关。
按照基因变异在疾病中发挥作用的程度可将疾病分为至少四类:1)完全由基因决定的:比如单基因罕见遗传病中的先天性成骨不全症、血友病、杜氏肌营养不良等。2)基本上由基因决定,但需要环境中的一定诱因:比如单基因遗传病中的苯丙酮尿症,早期人们只知道它与遗传有关,现在知道只有吃了含苯丙氨酸量多的食物才诱发此病;3)遗传因素和环境因素都有作用,这一类疾病里又分为主要由遗传因素决定的:如遗传性肿瘤,精神发育障碍等;以及遗传和环境同样重要的,如高血压、冠心病、糖尿病等各种慢病等;4)完全取决于环境因素:如烧烫伤、感染等。
根据国内外指南和专家共识,目前疾病与基因的关系又可简单分为5个等级。包括:
致病:一般指基因突变与疾病发病有这因果关系,都是在多个人群重复出了结果,并有可能开展了细胞动物实验得出的结果。
例如:因为ATP7B基因突变,所以导致ATP酶功能减弱或消失,引致血清铜蓝蛋白(Ceruloplasmin,CP)合成减少以及胆道排铜障碍,蓄积在体内的铜离子在肝、脑、肾、角膜等处沉积,引起肝豆状核变性(Hepatolenticular degeneration,HLD)。该病由Wilson在1912年首先描述,故又称为威尔逊病(Wilson Disease, WD)。是一种常染色体隐性遗传的铜代谢障碍性疾病,以铜代谢障碍引起的肝硬化、基底节损害为主的脑变性疾病为特点,对肝豆状核变性发病机制的认识已深入到分子水平。HLD的世界范围发病率为1/30 000~1/100 000,致病基因携带者约为1/90。本病在中国较多见。HLD好发于青少年,男性比女性稍多,如不恰当治疗将会致残甚至死亡。
含有致病突变的人相对于一般人有非常显著的高发病可能,纯合的致病突变很有可能直接导致疾病发生,杂合的致病突变有50%的几率遗传给后代,并根据遗传致病情况(显性遗传或隐性遗传)对后代造成不同的疾病表型。具有该类突变的患者应该进行相关疾病的特定检测,并根据临床结果制定后续治疗方案;
危险因素:一般指基因突变显著性的呈现在发病人群,在不/未发病人群里,这类基因突变显著降低。这里的显著,均值的统计学差异。然而这样的突变,目前仅通过了不同表型的人群分析出来了统计学差异,并没有发现病因学、病理学的差异以及信号通路上必然存在的变化,也没有相应的体内体外实验来验证其因果关系。
例如:β-微精浆蛋白(Microseminoprotein-beta, MSMB)是前列腺上皮细胞分泌的三大蛋白之一。Eeles et al.(2008)对1854名在60岁前诊断为前列腺癌的病人和1894名有低PSA浓度(less than 0.5 ng/ml)的正常人进行了基因组水平的研究,共分析了 541,129个SNPs。最终发现MSMB基因的此位点突变与前列腺癌显著相关 (8.7 x 10-29)。致病突变T,会影响众多与转录相关因子的结合。Thomas et al.(2008)对3941名前列腺癌病人和3964名正常人也进行了基因组水平的研究,共分析了26958个SNP,也发现MSMB基因的此位点突变与前列腺癌显著相关(7.31 x 10-13)。Chang et al.(2009)对2,899名病人和1722名健康人进行了研究,发现MSMB基因的此位点与前列腺癌的相关程度最高。Lou et al.(2009)对欧洲的6118名病人和6105名正常人的染色体10进行了研究,也发现了MSMB基因的此位点与前列腺癌显著相关程度最高(p = 8.8 x 10-18)。
危险因素级别的突变代表该基因位点与所检测的疾病相关性比较高,有该基因的突变,是发病的危险因素,与疾病的高发相关,具有该类突变的患者应该关注相关的健康管理和医疗。但由于科研深度有限,该突变不一定是疾病发生的原因。
不确定:代表该基因位点与所检测的疾病在不同研究中的结果不一样,有待更多的研究来进行核实该基因位点的改变与疾病发生的相关性;
良性:代表该基因位点虽然与一般人相比有改变,但是其改变与检测疾病无关;
风险未知:代表该基因位点虽然与一般人相比有改变,但目前并没有研究报道这个位点的改变与该疾病存在相关性。
通过基因测序,我们可以明确知道,一个人的变异位点中,有哪些是致病的突变,哪些是有危险因素的突变,这样才能根据基因检测结果对个人和后代是否患病进行准确性的判定。然后通过这些风险的评估,进行相应的个性化健康管理。
4疾病数据库的准确性与发展
然而,这些与疾病相关的突变不是凭空而来的,是科学家们日以继夜的科研累积,才能打开一点点疾病成因的未知世界。所以,我们必须建立一个能够快速查找上述DNA变异与疾病相关的数据库,才能在短时间内完成基因突变与疾病相关分析。
一个准确的数据库,可以让分析更准确,判断一个疾病的病因,进行正确的治疗。反之,一个不足准确的数据库,则可导致分析错误,甚至因此进行后续错误的治疗。在此可以举一个不足准确的数据库例子:
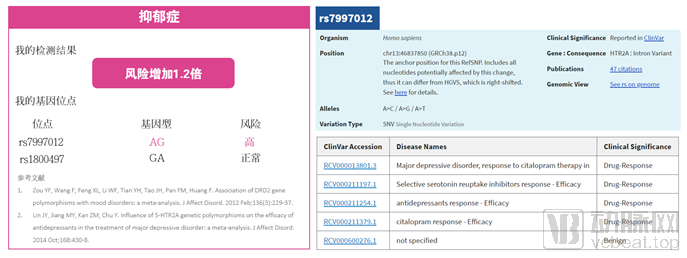
某基因检测公司的一份报告(左图),通过rs7997012这个SNP位点的杂合突变,该公司报告客户有抑郁症的风险。原因是所引用的这两篇文章。这两篇文章一篇发表于2012年,另一篇发表于2014年,都是来自一个叫“Journal of Affective Disorders”的杂志,影响因子3.5,且是做的荟萃分析(meta-analysis)。在没有阐述算法的前提下,我们可以先看该公司给出的检测基因位点:rs7997012。这个位点如右图所示(来源于NCBI),临床结论是治疗抑郁症的药物有效性,这个位点的突变会改变药物使用效果,而不是这个基因的突变会导致抑郁症的发病!因此,错误的数据库会导致基因检测的错误结论,哪怕检测出的基因型是正确的。
如果这个客户因为根据上述报告后续进行相关抑郁症治疗,那结果可能都是基于一个错误的判断。那么如何确定一个数据库是否可靠呢?
目前通用的做法是,整合国际上几个通用的人类基因组和疾病数据库,例如人类罕见病数据库OMIM(www.omim.org/),人类基因突变数据库(HGMD)(www.hgmd.cf.ac.uk/),临床方面疾病相关突变数据库Clinvar(www.ncbi.nlm.nih.gov/clinvar)等。同时,还要将最新的权威科研结果,例如发表在Science, Cell, NEJM, JAMA, Nature等顶级期刊的相关文章进行搜集整理,将这些整合在一起,成为一个公司的核心资产。以珠诺云公司为例,构建和维护疾病数据库的工作固定人员要超过5人,包括数据库架构师和管理员,以及对公共数据库和最新权威文献进行Review的科学家。工作流程是首先筛选公共数据库可靠的结果,将公共库评级等级高的位点整合进公司疾病数据库,再安排科学家进行Review,核对原文中该位点的生物学和医学意义,将有问题或者统计学没有显著性差异的位点排除后,把有意义的位点保留。另外,承担Review工作的科学家还会对最新发表的文献进行搜集和整理,将这些新文章中有意义的位点纳入公司疾病数据库。最后让数据库构架工程师对这些信息位点进行整理,形成可比对、可查询的疾病相关基因数据库。
这是每个基因检测公司的核心资产,也不太容易通过第三方进行合理评估。
最后,基因检测机构自有或国际公共疾病与基因突变数据库并不是一成不变的。从上世纪80年代PCR技术发明以后,人们逐步开始了解了基因突变和疾病的关系。如第3部分所述,一般来说,越严重的疾病越容易被更早的发现和基因突变的关系,如β地中海贫血;越温和的慢病,越不容易找到相关基因,必须做大人群样本的GWAS研究才能逐步了解基因和疾病的关系,如高血压、糖尿病等。
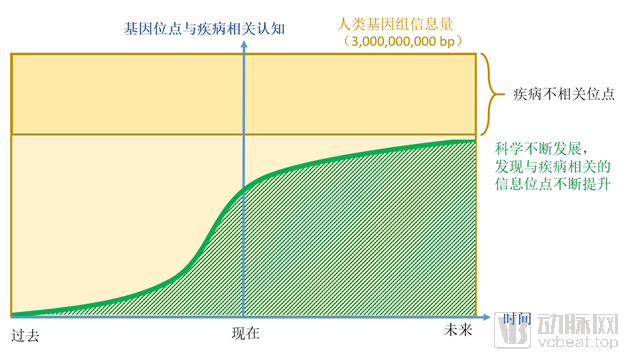
人类基因位点与疾病的相关性是不断进化的,我们正处在一个认知不断提升的阶段。通过过去的研究,我们已经逐步了解了一些基因突变和疾病的关系,多集中在罕见病、遗传性肿瘤领域;随着时间推移,科学不断发展,将会有越来越多的遗传信息位点会发现和疾病发病的相关性。
现在正处于一个基因与疾病相关性认知不断提升的阶段,因此,尽管已经知道了许多的基因突变可能造成疾病,但是仍有许多路要走。在不断的科技进步中,越来越多的疾病相关性位点会被发现,人类基因和疾病的关系也会越来越明朗。
5总结
当再次回到“基因检测的检验结果准确吗?”这样的问题时,通过上述阐述的内容就可以概括成:
1)测序结果与DNA实际的排列情况是否一致
对于测序的准确性来说,在一定的前提下,不管是一代测序(没有错峰套峰且背景干净),二代测序(保证测序深度和处理的算法效果),三代测序(保证测序深度和处理的算法效果)还是芯片(保证设计合理和有效结合)的结果,都是准确的,基因检测结果数据的准确性在不同平台用不同的测序手段都可以很好的实现,但各个技术最终能获得的有效信息量存在较大差异。
2)比对出的疾病易感位点,是否与疾病的发病真实相关
一般来说,基因检测出了疾病发病的风险,首先看致病等级,是致病?还是危险因素?还是其他。当出现了上述两种类型的位点时,就目前的数据来说是准确的。然而我们不可能了解到科学还没有触碰到的部分。因此从这个角度来看待结果,我们就不能确定检测是100%准确的。包括:测出有风险的位点,可能会通过今后的研究被推翻;以及测出没有风险的位点,会随着科研的进步而出现风险。此外,仍有大量未知的基因位点与疾病的相关性,随着科学的发展才能给予更笃定的证明。
因此在目前数据库可靠的前提下,对于人类已知的疾病发病位点,我们的检测保证与已有研究一致,则当下的基因检测就能保证接近100%的准确度。这里依然不排除现有的权威研究在补充了更大量的人群后,现有结果又被推翻。因此基因检测是一个不断发展的漫长过程,需要更多的从业者,做更大量的样本,这样才能在未来形成疾病与基因突变的正确认知,更好的回答“基因检测是否准确”这样的问题。

















